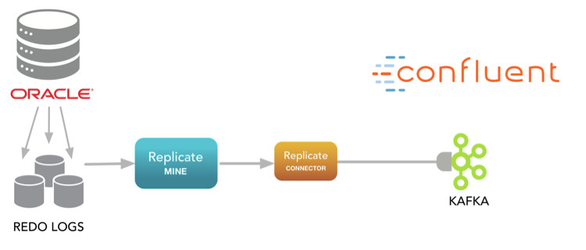
Dbvisit Replicate and the Dbvisit Replicate Connector for Kafka
...
The installation and configuration of Dbvisit Replicate, when supporting Kafka as a target, is basically the same as for a regular implementation. As such the general prerequisites and approach outlined in the Installing and Upgrading section of the user guide apply, and should be reviewed. You can install Dbvisit Replicate directly on the Oracle database server itself, use the lightweight FETCHER as an alternative to minimise any impact on the database server, or look at NFS mount options. Whatever option is chosen you need to ensure that the location the PLOG files Dbvisit Replicate generates will be accessible by the Replicate Connector for Kafka, which runs inside the Kafka Connect framework.
...
Download the Dbvisit Replicate software from the Dbvisit website and follow the user guide instructions to install the software on your server/platform.
...
We recommend you review both the Setup Wizard overview and the Setup Wizard Reference details prior to running the Setup Wizard itself.
...
If you choose not to run the scripts generated by the setup wizard (as in our example above) then you need to do so manually, and if they process through cleanly you can then start the replication and connect to the console to review its progress. So the steps are:
- Run the *.all.sh script (in our example above this is /home/oracle/REPCON-TEST/REPCON-TEST-all.sh)
- Start the replication (based on our example above the script to run for this, which will be produced as an output from the *-all.sh script, will be called REPCON-TEST-run-dbvrep01.sh)
- Start the Console
...
To monitor the Dbvisit Replicate once it is up and running there are a number of options available to you, and please follow the provided links for more information on each. Note that these notifications only inform about the operations of the Dbvisit Replicate MINE process, which itself is not aware of the Dbvisit Replicate Connection for Kafka operations and must be monitored separately.
the command console (which looks as follows):
No Format \ Dbvisit PureFlow 2.9.00(MAX edition) - Evaluation License expires in 60 days MINE is running. Currently at plog 1231 and SCN 27364050 (11/26/2016 08:53:32). Progress of replication REPCON:MINE->APPLY: total/this execution (stale) ------------------------------------------------------------------------------------------ SOE.CUSTOMERS: Mine:105171/105171 Unrecov:0/0 SOE.ADDRESSES: Mine:105359/105359 Unrecov:0/0 SOE.CARD_DETAILS: Mine:105232/105232 Unrecov:0/0 SOE.WAREHOUSES: Mine:1000/1000 Unrecov:0/0 SOE.ORDER_ITEMS: Mine:722468/722468 Unrecov:0/0 SOE.ORDERS: Mine:282339/282339 Unrecov:0/0 SOE.INVENTORIES: Mine:902640/902640 Unrecov:0/0 SOE.PRODUCT_INFORMATION: Mine:1000/1000 Unrecov:0/0 SOE.LOGON: Mine:769848/769848 Unrecov:0/0 SOE.PRODUCT_DESCRIPTIONS: Mine:1000/1000 Unrecov:0/0 SOE.ORDERENTRY_METADATA: Mine:4/4 Unrecov:0/0 SOE.TEST1: Mine:19/19 Unrecov:0/0 ------------------------------------------------------------------------------------------ 12 tables listed. dbvpf>
- Email (for the MINE process)
- SNMP (for the MINE process)
- Console silent mode operations, outlined in this Dbvisit blog post.
Operations
How do we regenerate a PLOG?
If PLOG files should become corrupted, or are deleted accidentally before being ingested to Kafka it is possible to recreate them. A PLOG can be regenerated by the MINE process, prodiving that the related redo/archive logs are available, using an internal engine command. Please see API and Internal Commands for more information.
The process is:
...