Dbvisit Replicate FETCHER Process
- KrupeshD (Deactivated)
- Arjen Visser
The FETCHER process is optional and is not needed when the MINE runs on the primary server. Using the FETCHER process is referred to as the Dbvisit Replicate 3 tier architecture.
Dbvisit Replicate 3 tier architecture with the FETCHER process
The 3-tier architecture is used to offload the MINE process to another server (downstream MINE). The processes in the 3-tier architecture are:
- FETCHER process
- MINE process
- APPLY process
All 3 processes can be run on different operating systems and are platform independent.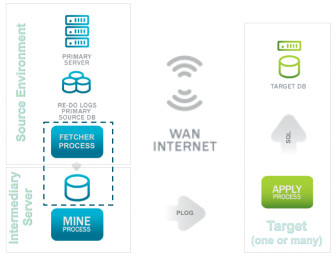
The direct impact of the FETCHER process on the source database is negligible, as it just stores small amount of state data and simple queries regarding current state of archive and online redo logs are issued against this database.
The MINE processes imposes a certain load on the source database when parsing the redo logs (CPU and memory). This maybe around 5% and may not be desirable in certain environments. This is when the FETCHER process is very useful. It runs on the source database, reading the redo logs and sending them to MINE process, which is running on a different machine.
The only operations the FETCHER process does are:
- queries the source database for the location of the redo logs.
- repeatedly queries the database to find out when the current log is switched.
- in case of ASM files, connects to ASM instance and reads the logs using internal PL/SQL API.
- in case of filesystem files, reads the files from disk using standard system I/O.
- connects to MINE over the network and transfers the redo log files to the MINE process.
- listens for user commands.
All of the resource-consuming work of parsing the redo logs, writing the PLOGS and sending them to APPLY is done by the MINE process.