Event Streaming Real-Time Data Warehousing
- Copy Space for Confluence
- Donna Zehl (Deactivated)
- Amy Hartnell (Deactivated)
One of the most complex issues in Data Warehousing is how to detect changes on your source system. Most data warehouses do a complete dump and load of all the data during the nightly load. With Dbvisit Replicate and the event streaming functionality, only data that has been changed can be loaded real time into the Data Warehouse. This allows for reduced processing and real time updates of the Data Warehouse.
The following operations are captured and written into a special created Dbvisit Replicate stage table in the target database:
- Inserts
- Updates
- Deletes
- Merge (this is translated to inserts and updates)
The following operations are NOT captured:
- Truncate
- Drop
- Create
The event streaming can also be used to capture auditing information for analysis purposes.
The event streaming information can be turned on during the setup wizard.
Event Streaming will only work for individual tables that are replicated. It is not supported if a whole schema is replicated.
Datatype considerations
The following datatypes are ignored by Event Streaming — the columns for capture are created, but will always contain NULL values. So considerations should be made if they can be excluded:
- CLOB
- BLOB
- UROWID
LONG datatypes should be excluded from tables included in Event Streaming replication as Oracle only permit one LONG datatype per table. Attempts to create, or have Dbvisit Replicate, create an Audit functionality enabled table on the target will throw a "ORA-01754: a table may contain only one column of type LONG" error. These columns can be excluded as per the following instructions.
How does Event Streaming work
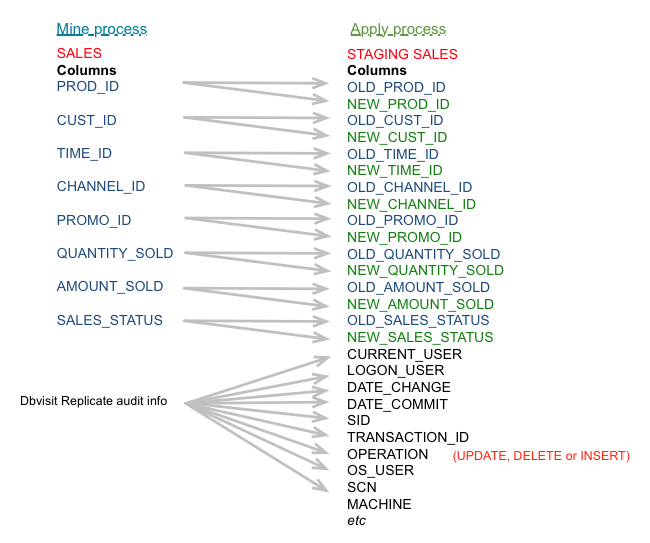
Dbvisit Replicate creates a copy of the source table as a staging table in the target database and inserts a record into this staging table every time there is a change in the source table (for Update, Delete, Insert). This means that even with an updated or delete in the source system, a new record is created in the target (or staging) table. The staging table holds a new record for every change in the source system.
The loading of the data warehouse process can use this staging table to process all new updates into the data warehouse. When the record has been processed and loaded into the data warehouse, the record can be removed from the staging table to indicate that the change has been loaded.
The staging table contains 2 columns for every 1 column on the source table. There is an OLD and NEW value. If a column is updated on the source table, then the replicated staging table will contain both the OLD and the NEW value.
Event streaming information is also written to the staging table.
This event streaming information contains:
- OPERATION
- SCN
- DATE_CHANGE
- TRANSACTION_ID
- DATE_COMMIT
- SSID
- SERIAL
- CURRENT_USER
- LOGON_USER
- CLIENT_INFO
- OS_USER
- MACHINE
- OS_TERM
- OS_PROC_ID
- OS_PROG
Example
The source database contains a table called SALES, and we want to capture all changes to this table into a staging table.
Dbvisit Replicate will create the DDL for the staging table which will contain:
- Duplicate of all columns with a prefix (this prefix is user specified)
- Extra metadata information
For every update, delete or insert transaction on the source database, a new record will be inserted into the staging table with the old and new values as they are applicable.
The OPERATION column of the staging table will contain the operation. This can be:
- I = INSERT
- U = UPDATE
- D = DELETE
If a column name is already of maximum length ( 30 characters) then Dbvisit Replicate implicitly renames such long column names on target, with old_ and new_ prefix, to keep the length of target column name 30 characters.
Dbvisit Replicate event streaming - loading of real-time data warehouses
Example of how the event streaming function works in Dbvisit Replicate to facilitate the ETL process for real-time loading of data warehouses. Length - 6:10
How to turn on event streaming
The event streaming function is turned on during the setup wizard.
Event streaming works for tables only not for schema replication.
Below example if for an Oracle target.
There are 5 steps to turning on the event streaming functionality:
1. Choose ddl-only in Step 2 - Replication pairs: "Lock and copy the data initially one-by-one or at a single SCN? (one-by-one/single-scn/ddl-only/resetlogs)"
2. Choose in ddl_file or ddl_run in Step 2 - Replication pairs: "What data copy script to create? (dp_networklink/dp_exp/exp/ddl_file/ddl_run/none)"
Step 2 - Replication pairs ======================================== The second step is to set source and targets for each replication pair. Let's configure the replication pair, selecting source and target. Following databases are described: 1: reptest1 (Oracle) 2: reptest2 (Oracle) Select source database: [1] Select target database: [2] Will DDL replication be enabled? [yes] Use fetcher to offload the mining to a different server? (yes/no) [no] Would you like to encrypt the data across the network (yes or no) [no] Would you like to compress the data across the network (yes or no) [no] How long do you want to set the network timeouts. Recommended range between 60-300 seconds [60] Lock and copy the data initially one-by-one or at a single SCN? one-by-one : Lock tables one by one and capture SCN single-scn : One SCN for all tables ddl-only : Only DDL script for target objects resetlogs : Use SCN from last resetlogs operation (standby activation, rman incomplete recovery) no-lock : Do not lock tables. Captures previous SCN of oldest active transaction. Requires pre-requisite running of pre-all.sh script (one-by-one/single-scn/ddl-only/resetlogs/no-lock) [single-scn] ddl-only What data instantiation script to create? dp_networklink : Data Pump with network link. No export datafile is created (APPLY.sh) dp_exp : Data Pump with export datafile. Creates an export datafile (APPLY.sh) exp : Pre-datapump exp/imp with export datafile (APPLY.sh) ddl_file : DDL file created (APPLY.sql) ddl_run : DDL is automatically executed on target load : All replicated data is created and loaded automatically none (dp_networklink/dp_exp/exp/ddl_file/ddl_run/load/none) [ddl_file] ddl_run Following replication pairs are now configured: 1: reptest1 (Oracle) ==> reptest2 (Oracle), DDL: yes, fetcher: no, process suffix: (no suffix), compression: no, encryption: no, network timeout: 60, prepare type: ddl-only, data load: ddl_run Enter number of replication pair to modify it, or "add", or "done": [done]
3. Choose yes in Step 3 - Replicated tables:"Specify rename name, filter condition, CDC/Audit/ETL for any of the specified tables (yes/no):"
4. Choose yes in Step 3 - Replicated tables: "Configure change data capture for change auditing or BI? (yes/no)"
5. Once Audit is turned on, the setup wizard will ask more questions to specifically configure Audit for each particular need:
Step 3 - Replicated tables ======================================== The third step is to choose the schemas and tables to be replicated. If the databases are reachable, the tables are checked for existence, datatype support, etc., schemas are queried for tables. Note that all messages are merely hints/warnings and may be ignored if issues are rectified before the scripts are actually executed. Following tables are defined for replication pairs: 1: reptest1 (Oracle) ==> reptest2 (Oracle), DDL: yes, suffix: (no suffix), prepare: ddl-only No tables defined. Enter number of replication pair to modify it, or "done": [1] Please enter list of all individual tables to be replicated. Enter schema name(s) only to replicate all tables in that schema. Use comma or space to delimit the entries. Enter the tables and schemas: [] test1.temp1 Selected tables: TEST1.TEMP1 Add more tables or schemas? (YES/NO) [NO] To replicate changes of PL/SQL objects in schema(s), please enter the schemas to be replicated. Note that specifying any entry will cause additional privileges to be granted to dbvrep. Enter through a comma or space-delimited list. Enter the list of schemas (PL/SQL): [] You can also specify some advanced options: 1. Exclude some tables from schema-level replication 2. Rename schemas or tables. 3. Specify filtering conditions. 4. (Tables only) Configure Change Data Capture; this does not maintain a copy of the source table, but logs all operations as separate entries. This is useful for ETL or as an audit trail. This usually requires adding of new columns (timestamps, old/new values etc.) to the target table. Specify rename name, filter condition, CDC/Audit/ETL for any of the specified tables (yes/no): [no] yes Rename SCHEMA name for TEST1.TEMP1 (empty means no rename): [] Rename TABLE name for TEST1.TEMP1 (empty means no rename): [] Filter the data to be replicated? If yes, use single condition for ALL DML operations or use CUSTOM conditions for each operation? (NO/ALL/CUSTOM) [NO] Configure change data capture for change auditing or real-time BI? (NO/YES) [NO] yes Capture DELETE operations? (YES/NO) [YES] Capture UPDATE operations - old values? (YES/NO) [YES] Capture UPDATE operations - new values? (YES/NO) [YES] Capture INSERT operations? (YES/NO) [YES] The columns at the target table can be called the same as on the source table, or they can be prefixed to indicate whether they contain old or new values. As both new and old values for update are specified, at least one prefix has to be defined. Prefix for columns with OLD values: [] old_ Prefix for columns with NEW values: [] new_ Dbvisit Replicate can include additional information into the target table; this can be used to identify type of change, when it occurred, who initiated the change etc. Add basic additional information about the changes? (SCN, time, operation type) (YES/NO) [YES] Add more transactional information? (transaction id, commit time) (YES/NO) [NO] yes Add auditing columns? (login user, machine, OS user...) (YES/NO) [NO] yes Setup wizard chose following default names for the columns; you can use them or choose own names. Note that empty answer confirms the proposed default; use "-" (minus) to remove the column from the CDC. CLIENT_INFO: Client info (cliinfo) CURRENT_USER: Current user (cuser) LOGON_USER: Logon user (luser) MACHINE: Client machine name (machine) OPERATION: Operation code (U/I/D) (opcol) OS_PROC_ID: OS process id (osproc) OS_PROG: OS program name (osprog) OS_TERM: OS terminal (osterm) OS_USER: OS user (osuser) SCN: SCN at source (scn) SERIAL: Oracle session serial# (serial) SID: Oracle session ID (sid) DATE_CHANGE: Date and time of the change (timestamp_change) DATE_COMMIT: Date and time of transaction commit (timestamp_commit) TRANSACTION_ID: Transaction ID (mandatory if timestamp_commit is used; please define an index on transaction ID in such case) (xidcol) TRANSACTION_NAME: Transaction name (xidname) Accept these settings? (YES/NO) [YES] Following tables are defined for replication pairs: 1: reptest1 (Oracle) ==> reptest2 (Oracle), DDL: yes, suffix: (no suffix), prepare: ddl-only TEST1.TEMP1 Enter number of replication pair to modify it, or "done": [done]
Manually turning on Event Streaming
The Event Streaming function can also be turn on manually. This can be done in the dbvrep console.
Example:
To manually turn on Event Streaming for a table called AVI.SALES, issue the following commands:
PREPARE TABLE AVI.SALES CDCAUDIT TABLE AVI.SALES INSERT YES CDCAUDIT TABLE AVI.SALES DELETE YES CDCAUDIT TABLE AVI.SALES UPDATE YES CDCAUDIT TABLE AVI.SALES OLDCOL_PREFIX OLD_ CDCAUDIT TABLE AVI.SALES NEWCOL_PREFIX NEW_ CDCAUDIT TABLE AVI.SALES OPCOL OPERATION CDCAUDIT TABLE AVI.SALES SCN SCN CDCAUDIT TABLE AVI.SALES TIMESTAMP_CHANGE DATE_CHANGE CDCAUDIT TABLE AVI.SALES XIDCOL TRANSACTION_ID CDCAUDIT TABLE AVI.SALES TIMESTAMP_COMMIT DATE_COMMIT CDCAUDIT TABLE AVI.SALES SID SID CDCAUDIT TABLE AVI.SALES SERIAL SERIAL CDCAUDIT TABLE AVI.SALES CUSER CURRENT_USER CDCAUDIT TABLE AVI.SALES LUSER LOGON_USER CDCAUDIT TABLE AVI.SALES CLIINFO CLIENT_INFO CDCAUDIT TABLE AVI.SALES OSUSER OS_USER CDCAUDIT TABLE AVI.SALES MACHINE MACHINE CDCAUDIT TABLE AVI.SALES OSTERM OS_TERM CDCAUDIT TABLE AVI.SALES OSPROC OS_PROC_ID CDCAUDIT TABLE AVI.SALES OSPROG OS_PROG
This also turns on all auditing columns available. You use command "DDL CREATE PRINT AVI.SALES" for creation of table to target database. Remember to restart mine and apply process then.
The changes are inserted as they are fed from mine, i.e. they can stay inserted but uncommitted until the transaction commits on the source database. When using the event streaming option, this means that the application that reads the event streaming data must not rely solely on the SCN/time of the change to determine whether a record was processed (that's what the commit SCN is for). And it also means that the purging of old partitions must not be too aggressive, as they can still contain uncommitted rows.
Note that the commit SCN is inserted as NULL and updated only when the commit actually comes in. (This means the transaction id should be indexed if commit SCN column is used and that you need row movement enabled if you use that as partition key.)
How to purge older event streaming inserted data?
Options to purge data out of the Audit inserted staging tables are:
- Delete each record as they are processed and loaded by the ETL process.
- Convert the target Audit inserted staging tables to partitioned tables (if this option is licensed).
The changes are inserted as they are fed from mine, i.e. they can stay inserted but uncommitted until the transaction commits on the source database. This means that the application that reads the event streaming data must not rely solely on the SCN/time of the change to determine whether a record was processed (that's what the commit SCN is for). And it also means that the purging of old partitions must not be too aggressive, as they can still contain uncommitted rows. The commit SCN is inserted as NULL and updated only when the commit actually comes in. (This means the transaction id should be indexed if commit SCN column is used and that you need row movement enabled if you use that as partition key.)
See also: DbvisitUniversity Training
Event Streaming for Data Warehousing
Learn how you can make the most of your data with Dbvisit Replicate's awesome Event Streaming function.