Target Kafka (via Kafka Connect)
- Deepika Kumar (Deactivated)
- Mike Donovan (Deactivated)
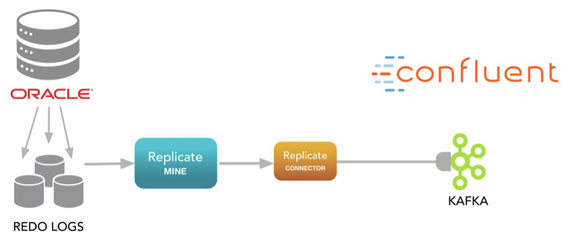
Dbvisit Replicate and the Dbvisit Replicate Connector for Kafka
Dbvisit Replicate supports the streaming of Oracle database change data (inserts, deletes, updates and limited DDL) to Kafka as a target, via an open source Java connector, initiated by the Dbvisit team - the Dbvisit Replicate Connector for Kafka. This connector runs within the Kafka Connect framework developed by Confluent, which itself can be thought of as an import/export layer for Kafka, simplifying both data ingest and output to various endpoints, from Kafka.
Overview
Dbvisit Replicate's MINE process generates PLOG files in the regular manner and delivers these to a location accessible by the Replicate Connector for Kafka. In this configuration there is no partner APPLY process that runs, as the Replicate Connector effectively picks up this function. The connector itself runs within the Kafka Connect framework, and we recommend installing the Confluent Platform for this. Key resources are listed below:
- Dbvisit Replicate Connector for Kafka GitHub Repository
- Dbvisit Replicate Connector for Kafka Documentation
- Kafka Connect Hub
- Confluent Platform Downloads and Information
Notes and Limitations
NOTE
- Only limited DDL replication is currently supported for Kafka as a target (add tables, add column, remove column).
- Two-way replication with Kafka (as also for other non-Oracle targets) is not currently supported.
Setup Outlined
The installation and configuration of Dbvisit Replicate, when supporting Kafka as a target, is basically the same as for a regular implementation. As such the general prerequisites and approach outlined in the Installing and Upgrading section of the user guide apply, and should be reviewed. You can install Dbvisit Replicate directly on the Oracle database server itself, use the lightweight Fetcher as an alternative to minimise any impact on the database server, or look at NFS mount options. Whatever option is chosen you need to ensure that the location the PLOG files Dbvisit Replicate generates will be accessible by the Replicate Connector for Kafka, which runs inside the Kafka Connect framework.
At a high level the setup process for the Dbvisit Replicate piece of this configuration is as follows:
- install the Dbvisit Replicate software - and this only needs to be done for the source side against which the MINE process will run
- rename the executable to dbvpf
- configure the replication (the MINE process) using the setup wizard
The Process
Installing the software
Download the Dbvisit Replicate software from the Dbvisit website and follow the user guide instructions to install the software on your server/platform.
Rename the dbvrep executable
In order to trigger specific functionality in support of Kafka as a target the dbvrep executable needs to be renamed to dbvpf. To do so navigate to your Dbvisit Replicate installation directory and, as a user with appropriate privileges to do so, rename the executable as follows:
[root@dbvrep01 /usr/dbvisit/replicate] # mv dbvrep dbvpf [root@dbvrep01 /usr/dbvisit/replicate] # ls -ltr total 66340 -rw-r--r-- 1 root root 100518 Oct 27 05:42 README.txt -rw-r--r-- 1 root root 120 Oct 27 05:42 online_user_guide_reference_dbvrep.txt -rwxr-xr-x 1 root root 67806725 Oct 27 05:42 dbvpf -rw-r--r-- 1 root root 15892 Oct 27 05:42 Dbvisit-MIB-SNMP.txt [root@dbvrep01 /usr/dbvisit/replicate] #
Run the setup wizard
You can then invoke the Dbvisit Replicate console, by calling the executable as follows, and launching the setup wizard to configure the replication:
[oracle@dbvrep01 REPCON]$ /usr/dbvisit/replicate/dbvpf Initializing......done Dbvisit PureFlow version 2.8.02_rc2 Copyright (C) Dbvisit Software Limited. All rights reserved. No DDC file loaded. Run "setup wizard" to start the configuration wizard or try "help" to see all commands available. dbvpf> setup wizard [Integration option enabled] This wizard configures Dbvisit PureFlow. The setup wizard creates configuration scripts, which need to be run after the wizard ends. No changes to the databases are made before that. The progress is saved every time a list of databases, replications, etc. is shown. It will be re-read if wizard is restarted and the same DDC name and script path is selected. Run the wizard now? [Yes]
Setup Wizard Options Available
We recommend you review both the Setup Wizard overview and the Setup Wizard Reference details prior to running the Setup Wizard itself.
The key point to be aware of when running this in the context of setting up Kafka as a target (dbvpf/Replicate Connector for Kafka) is that you will be presented with less options in the wizard due to the nature of the target itself and because you will not be configuring an APPLY process. This piece of the replication will be handled by the Replicate Connector for Kafka, running inside Kafka Connect, with its own set of configuration options and requirements.
As a starting point going with many of the default options provided in the Setup Wizard will be sufficient to get you going, but a couple of parameters are worth commenting on:
- LOAD - selecting this option under "Step 2 - Replication pairs > What data instantiation script to create?" uses built in functionality in Dbvisit Replicate to select all existing information from a table(s) and deliver this to Kafka, to initialise or baseline these data sets in Kafka itself, as outlined in the connector documentation.
- Replicated Tables - this is the key step of identifying those Oracle schemas and tables you want to have replicated through to Kafka - and each must be specifically included here.
- Limited DDL - under "Step 2 - Replication pairs > Will limited DDL replication be enabled?" you can choose to enable/disable the limited DDL options supported for deliver to Kafka. If this is set to yes and you have included schema(s) level replication then any new tables created under that schema(s) will be replicated through to Kafka also.
- Where Clauses and ALL Columns - supplemental logging needs to be enabled for ALL columns with dbvpf for delivery to Kafka. Answering Yes to this question will set this accordingly in the configuration files.
Setup Wizard Example
[oracle@dbvrep01 REPCON]$ /usr/dbvisit/replicate/dbvpf Initializing......done Dbvisit PureFlow version 2.8.02_rc2 Copyright (C) Dbvisit Software Limited. All rights reserved. No DDC file loaded. Run "setup wizard" to start the configuration wizard or try "help" to see all commands available. dbvpf> setup wizard [Integration option enabled] This wizard configures Dbvisit PureFlow. The setup wizard creates configuration scripts, which need to be run after the wizard ends. No changes to the databases are made before that. The progress is saved every time a list of databases, replications, etc. is shown. It will be re-read if wizard is restarted and the same DDC name and script path is selected. Run the wizard now? [Yes] yes Before starting the actual configuration, some basic information is needed. The DDC name and script path determines where all files created by the wizard go (and where to reread them if wizard is rerun) and the license key determines which options are available for this configuration. (DDC_NAME) - Please enter a name for this replication: [] REPCON-TEST (LICENSE_KEY) - Please enter your license key: [I0JSW-898RU-TL6QF-BJLHR-0U7GN-M99I2-F2OP5] (SETUP_SCRIPT_PATH) - Please enter a directory for location of configuration scripts on this machine: [/home/oracle/REPCON-TEST] Network configuration files were detected on this system in these locations: /u01/app/oracle/product/11.2.0/xe/network/admin (TNS_ADMIN) - Please enter TNS configuration directory for this machine: [/u01/app/oracle/product/11.2.0/xe/network/admin] Step 1 - Describe databases ======================================== The first step is to describe databases used in the replication. There are usually two of them (source and target). Store SYSDBA and DBA passwords? Passwords only required during setup and initialization? (Yes/No) [Yes] Let's configure the database, describing its type, connectivity, user names etc. What type of database is this? (Oracle/MySQL/Google Cloud SQL/SQL Server/Oracle AWS RDS/CSV/Hadoop): [Oracle] Please enter database TNS alias: [] XE Please enter SYSDBA user name: [SYS] Please enter password for this user: [change_on_install] Please enter user with DBA role: [SYSTEM] Please enter password for this user: [manager] Connecting to database XE as SYSTEM to query list of tablespaces and to detect ASM (by looking whether any redo logs or archived logs are stored in ASM). Enter the Dbvisit PureFlow owner (this user will be created by this script): [dbvrep] Please enter password for this user: [dbvpasswd] Permanent tablespaces detected on the database: DATA, USERS. Please enter default permanent tablespace for this user: [DATA] USERS Temporary tablespaces detected on the database: TEMP. Please enter default temporary tablespace for this user: [TEMP] Following databases are now configured: 1: Oracle XE, SYS/***, SYSTEM/***, dbvrep/***, USERS/TEMP, dbvrep/, ASM:No, TZ: +00:00 Enter the number of the database to modify it or "done": [done] Step 2 - Replication pairs ======================================== The second step is to set source and targets for each replication pair. Let's configure the replication pair, selecting source and target. Following databases are described: 1: XE (Oracle) 2: Dbvisit PureFlow (dbvpf) (cannot be source, is not Oracle) Select source database: [1] Select target database: [2] Will limited DDL replication be enabled? (Yes/No) [Yes] Use fetcher to offload the mining to a different server? (Yes/No) [No] Should where clauses (and Event Streaming) include all columns, not just changed and PK? (Yes/No) [Yes] Would you like to encrypt the data across the network? (Yes/No) [No] Would you like to compress the data across the network? (Yes/No) [No] How long do you want to set the network timeouts. Recommended range between 60-300 seconds [60] Lock and copy the data initially one-by-one or at a single SCN? one-by-one : Lock tables one by one and capture SCN single-scn : One SCN for all tables ddl-only : Only DDL script for target objects resetlogs : Use SCN from last resetlogs operation (standby activation, rman incomplete recovery) no-lock : Do not lock tables. Captures previous SCN of oldest active transaction. Requires pre-requisite running of pre-all.sh script (one-by-one/single-scn/ddl-only/resetlogs/no-lock) [single-scn] no-lock What data instantiation script to create? scn_list : A file with SCN for every replicated object is created (APPLY.txt) load : All replicated data is created and loaded automatically none (scn_list/load/none) [scn_list] load Following replication pairs are now configured: 1: XE (Oracle) ==> Dbvisit PureFlow (dbvpf), DDL: Yes, fetcher: No, process suffix: (no suffix), compression: No, encryption: No, network timeout: 60, prepare type: no-lock, data load: load_keep Enter number of replication pair to modify it, or "add", or "done": [done] Step 3 - Replicated tables ======================================== The third step is to choose the schemas and tables to be replicated. If the databases are reachable, the tables are checked for existence, datatype support, etc., schemas are queried for tables. Note that all messages are merely hints/warnings and may be ignored if issues are rectified before the scripts are actually executed. Following tables are defined for replication pairs: 1: XE (Oracle) ==> Dbvisit PureFlow (dbvpf), DDL: Yes, suffix: (no suffix), prepare: no-lock No tables defined. Enter number of replication pair to modify it, or "done": [1] Please enter list of all individual tables to be replicated. Enter schema name(s) only to replicate all tables in that schema. Use comma or space to delimit the entries. Enter the tables and schemas: [] SOE,SCOTT Selected schemas: SCOTT,SOE Add more tables or schemas? (Yes/No) [No] You can also specify some advanced options: 1. Exclude some tables from schema-level replication 2. Rename schemas or tables. 3. Specify filtering conditions. 4. (Tables only) Configure Event Streaming; this does not maintain a copy of the source table, but logs all operations as separate entries. This is useful for ETL or as an audit trail. This usually requires adding of new columns (timestamps, old/new values etc.) to the target table. Specify rename name, filter condition or audit for any of the specified schemas? (Yes/No) [No] (PREPARE_SCHEMA_EXCEPTIONS) - Specify tables to exclude from PREPARE SCHEMA, if any: [] Following tables are defined for replication pairs: 1: XE (Oracle) ==> Dbvisit PureFlow (dbvpf), DDL: Yes, suffix: (no suffix), prepare: no-lock SCOTT(tables), SOE(tables) Enter number of replication pair to modify it, or "done": [done] Step 4 - Process configuration ======================================== The fourth step is to configure the replication processes for each replication. Following processes are defined: 1: MINE on XE Not configured. Enter number of process to modify it, or "done": [1] Fully qualified name of the server for the process (usually co-located with the database, unless mine is offloaded using fetcher): [dbvrep01] Server type (Windows/Linux/Unix): [Linux] Enable email notifications about problems? (Yes/No) [No] Enable SNMP traps/notifications about problems? (Yes/No) [No] Directory with DDC file and default where to create log files etc. (recommended: same as global setting, if possible)? [/home/oracle/REPCON-TEST] Following settings were pre-filled with defaults or your reloaded settings: ---------------------------------------- [MINE_REMOTE_INTERFACE]: Network remote interface: dbvrep01:7901 [MINE_DATABASE]: Database TNS: XE [TNS_ADMIN]: tnsnames.ora path: /u01/app/oracle/product/11.2.0/xe/network/admin [MINE_PLOG]: Filemask for generated plogs: /home/oracle/REPCON-TEST/mine/%S.%E.%Z (%S is sequence, %T thread, %F original filename (stripped extension), %P process type, %N process name, %E default extension) [LOG_FILE]: General log file: /home/oracle/REPCON-TEST/log/dbvpf_%N_%D.%E [LOG_FILE_TRACE]: Error traces: /home/oracle/REPCON-TEST/log/trace/dbvpf_%N_%D_%I_%U.%E Checking that these settings are valid... Do you want to change any of the settings? [No] Following processes are defined: 1: MINE on XE Host: dbvrep01, SMTP: No, SNMP: No Enter number of process to modify it, or "done": [done] Created file /home/oracle/REPCON-TEST/REPCON-TEST-MINE.ddc. Created file /home/oracle/REPCON-TEST/config/REPCON-TEST-setup.dbvpf. Created file /home/oracle/REPCON-TEST/config/REPCON-TEST-dbsetup_XE_dbvrep.sql. Created file /home/oracle/REPCON-TEST/config/REPCON-TEST-grants_XE_dbvrep.sql. Created file /home/oracle/REPCON-TEST/config/REPCON-TEST-pre-suplog_XE_dbvrep.sql. Created file /home/oracle/REPCON-TEST/REPCON-TEST-pre-all.sh. Created file /home/oracle/REPCON-TEST/config/REPCON-TEST-onetime.ddc. Created file /home/oracle/REPCON-TEST/start-console.sh. Created file /home/oracle/REPCON-TEST/REPCON-TEST-run-dbvrep01.sh. Created file /home/oracle/REPCON-TEST/scripts/REPCON-TEST-dbvrep01-start-MINE.sh. Created file /home/oracle/REPCON-TEST/scripts/REPCON-TEST-dbvrep01-stop-MINE.sh. Created file /home/oracle/REPCON-TEST/scripts/REPCON-TEST-dbvrep01-dbvpf-MINE.sh. Created file /home/oracle/REPCON-TEST/scripts/systemd-dbvpf-MINE_REPCON-TEST.service. Created file /home/oracle/REPCON-TEST/scripts/upstart-dbvpf-MINE_REPCON-TEST.conf. Created file /home/oracle/REPCON-TEST/Nextsteps.txt. Created file /home/oracle/REPCON-TEST/REPCON-TEST-all.sh. =========================================================================================================================================================== Dbvisit PureFlow wizard completed Script /home/oracle/REPCON-TEST/REPCON-TEST-pre-all.sh created. This needs to be run when transactions are not active on source database either during maintenance window or when there is no/low activity on source database. Script /home/oracle/REPCON-TEST/REPCON-TEST-all.sh created. This runs all the above created scripts. Please exit out of dbvpf, review and run script as current user to setup and start Dbvisit PureFlow. =========================================================================================================================================================== Optionally, the script can be invoked now by this wizard. Run this script now? (Yes/No) [No] dbvpf> exit
Completing the Configuration Setup
If you choose not to run the scripts generated by the setup wizard (as in our example above) then you need to do so manually, and if they process through cleanly you can then start the replication and connect to the console to review its progress. So the steps are:
- Run the *.all.sh script (in our example above this is /home/oracle/REPCON-TEST/REPCON-TEST-all.sh)
- Start the replication (based on our example above the script to run for this, which will be produced as an output from the *-all.sh script, will be called REPCON-TEST-run-dbvrep01.sh)
- Start the Console
Monitoring
To monitor the Dbvisit Replicate once it is up and running there are a number of options available to you, and please follow the provided links for more information on each. Note that these notifications only inform about the operations of the Dbvisit Replicate MINE process, which itself is not aware of the Dbvisit Replicate Connection for Kafka operations and must be monitored separately.
the command console (which looks as follows):
\ Dbvisit PureFlow 2.8.02_rc2(MAX edition) - Evaluation License expires in 60 days MINE is running. Currently at plog 1231 and SCN 27364050 (11/26/2016 08:53:32). Progress of replication REPCON:MINE->APPLY: total/this execution (stale) ------------------------------------------------------------------------------------------ SOE.CUSTOMERS: Mine:105171/105171 Unrecov:0/0 SOE.ADDRESSES: Mine:105359/105359 Unrecov:0/0 SOE.CARD_DETAILS: Mine:105232/105232 Unrecov:0/0 SOE.WAREHOUSES: Mine:1000/1000 Unrecov:0/0 SOE.ORDER_ITEMS: Mine:722468/722468 Unrecov:0/0 SOE.ORDERS: Mine:282339/282339 Unrecov:0/0 SOE.INVENTORIES: Mine:902640/902640 Unrecov:0/0 SOE.PRODUCT_INFORMATION: Mine:1000/1000 Unrecov:0/0 SOE.LOGON: Mine:769848/769848 Unrecov:0/0 SOE.PRODUCT_DESCRIPTIONS: Mine:1000/1000 Unrecov:0/0 SOE.ORDERENTRY_METADATA: Mine:4/4 Unrecov:0/0 SOE.TEST1: Mine:19/19 Unrecov:0/0 ------------------------------------------------------------------------------------------ 12 tables listed. dbvpf>
- Email (for the MINE process)
SNMP (for the MINE process)